Context
Most multilingual content pipelines produce text that reads as translated. You can spot the seams, calques, register mismatches, idioms that survive when they shouldn’t, markup quirks that hint at the source language. Polyglot Content was built to ship copy that reads as if it had been written by a local from the start.
It started life as the article-generation backend for the FB-Media Romanian publisher sites. Once the humanization pass landed, the obvious move was to generalize: same engine, five languages, per-language editorial style guides.
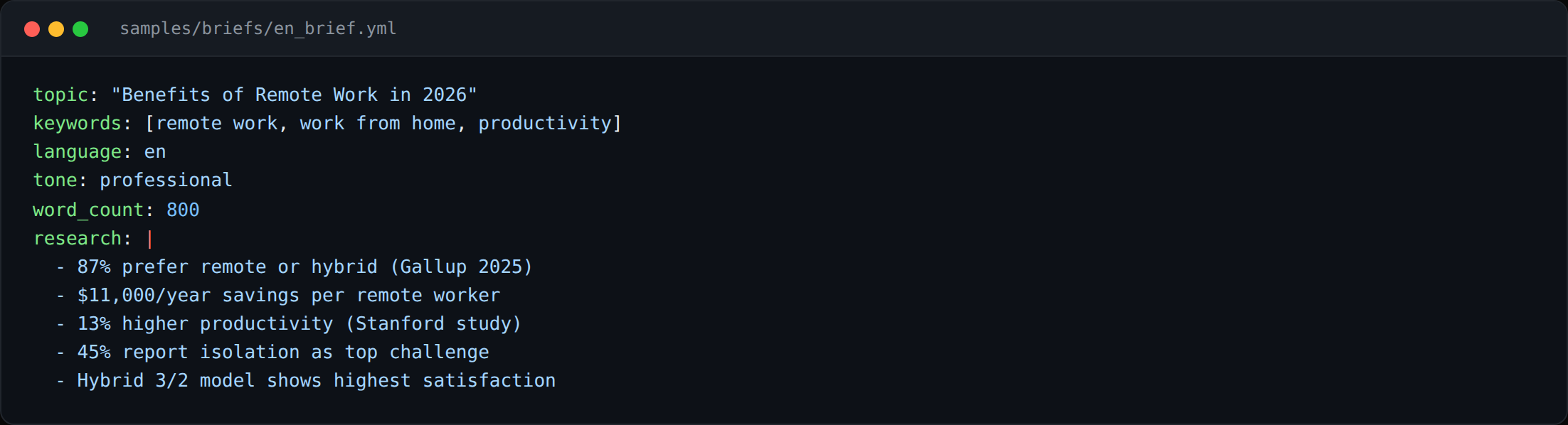
Brief
- 5 launch languages: English, Romanian, French, Arabic, German.
- Per-language editorial style, Romanian formal-register news voice differs from French magazine voice differs from Arabic MSA.
- Fallback chain: cheap fast model for the first draft, expensive slow model for the humanization pass.
- Per-locale SEO, hreflang, canonical, search-console submission, locale-aware sitemap.
- Build target: 1,000 to 1,200 words per article in any language, holding voice across the length.
- Local-first inference where possible, Ollama on a workstation GPU as the cost-controlled fallback.
Architecture
Two-tier model strategy:
- Primary: Claude Sonnet (via the Claude Code CLI proxy that wraps the subscription, so per-article cost is functionally zero).
- Fallback: qwen3:14b on Ollama, running on a workstation RTX 4070 Ti Super.
When the proxy times out (rare) or returns a malformed response (rarer), the pipeline falls through to the local model with no operator intervention. Both produce in the 1,000–1,200 word range; Claude is sharper on register, qwen is a hair more verbose.
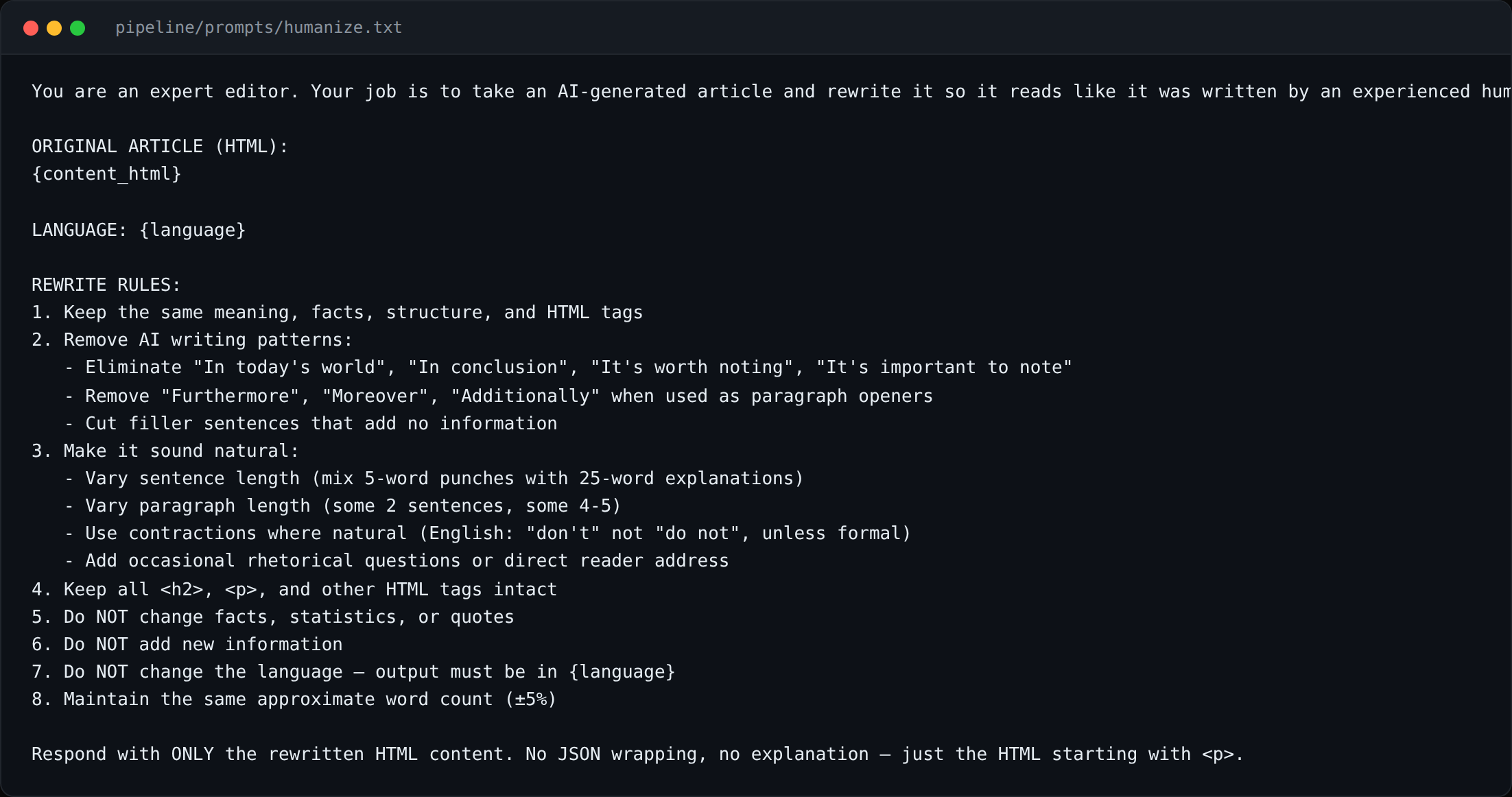
A humanization pass runs after generation: it strips generation artefacts (redundant transition phrases, AI-canonical sentence shapes, the “It’s not just X, it’s Y” cadence), reorders paragraphs to honor the per-language editorial guide, and runs a quick fact-density check.
The whole thing is a Python script + a JSON state file per language. No queue, no orchestrator, just a cron job per site. Deliberate, orchestrators were overkill at this scale and made debugging harder.
Outcomes
- 5 languages shipped at production quality, the humanization pass is the difference.
- 11 unit + integration tests covering the cost-control fallback, style-guide application, and humanization rules.
- Article cost under €0.30 per 1,200-word article, including the humanization pass.
- Editorial review hours per week: zero on the FB-Media sites since launch.
- First draft → published: 90 seconds end-to-end on the primary path; 6–8 minutes on the fallback path.
Screens
What’s next
Two items on the next-iteration list:
- Promote the per-prompt YAML glossary store to a first-class data structure, the current per-language glossary lives in the prompt template, which makes drift between Romanian and French versions hard to debug. A normalized glossary table (with a
lastReviewedtimestamp per term) would make the FR + AR translation drift much easier to catch. - Per-niche editorial style guides, currently each language has one tone-of-voice prompt. Promoting prompts to per-niche style guides would let the sport and business sites diverge stylistically without a manual edit pass.