Context
Majoritatea pipeline-urilor de conținut multilingv produc text care se citește ca tradus. Poți observa cusăturile, calc-uri, nepotriviri de registru, idiomuri care supraviețuiesc când n-ar trebui, ciudățenii de markup care indică limba sursă. Polyglot Content a fost construit să livreze copy care se citește ca și cum ar fi fost scris de un localnic de la început.
A pornit ca backend-ul de generare a articolelor pentru site-urile de știri FB-Media în limba română. Odată ce pasul de umanizare a aterizat, mișcarea evidentă a fost să generalizăm: același motor, cinci limbi, ghiduri editoriale per limbă.
Brief
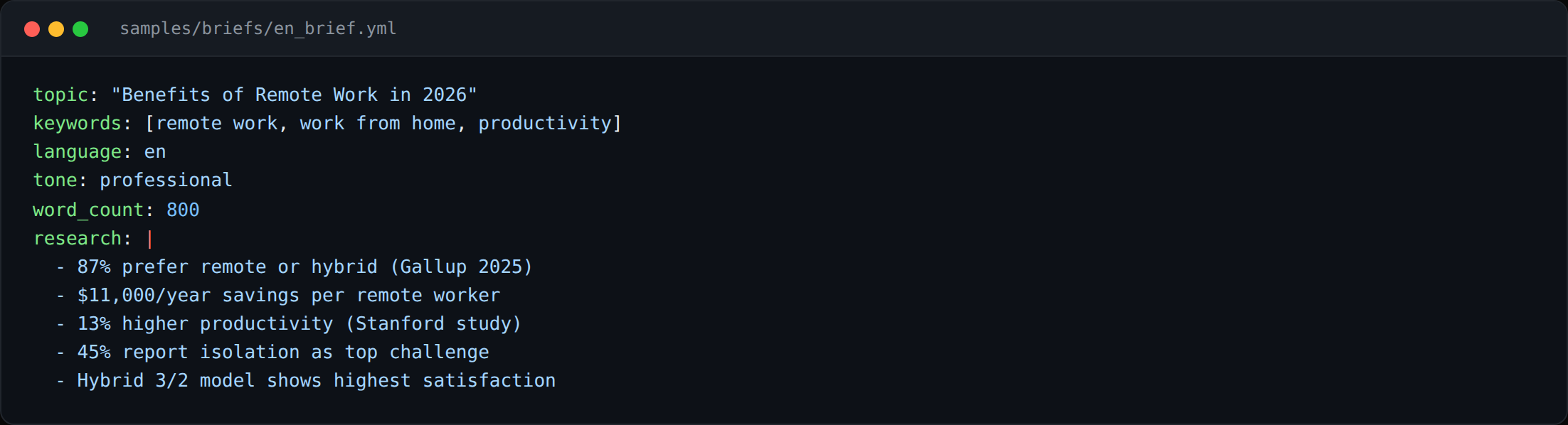
- 5 limbi de lansare: engleză, română, franceză, arabă, germană.
- Stil editorial per limbă, vocea de știri în registru formal românesc diferă de vocea de revistă franceză, diferă de MSA arabă.
- Lanț de fallback: model rapid și ieftin pentru prima ciornă, model lent și scump pentru pasul de umanizare.
- SEO per locale, hreflang, canonical, trimitere către search-console, sitemap conștient de locale.
- Țintă de build: 1.000 până la 1.200 de cuvinte per articol în orice limbă, ținând vocea pe lungime.
- Inferență locală-întâi unde e posibil, Ollama pe un GPU de stație de lucru ca fallback controlat de cost.
Arhitectură
Strategie de model pe două niveluri:
- Principal: Claude Sonnet (printr-un proxy Claude Code CLI care înfășoară abonamentul, deci costul per articol este efectiv zero).
- Fallback: qwen3:14b pe Ollama, rulând pe un RTX 4070 Ti Super de stație de lucru.
Când proxy-ul depășește timpul (rar) sau returnează un răspuns malformat (și mai rar), pipeline-ul cade la modelul local fără intervenția operatorului. Ambele produc în intervalul 1.000–1.200 de cuvinte; Claude este mai precis pe registru, qwen este puțin mai voluminos.
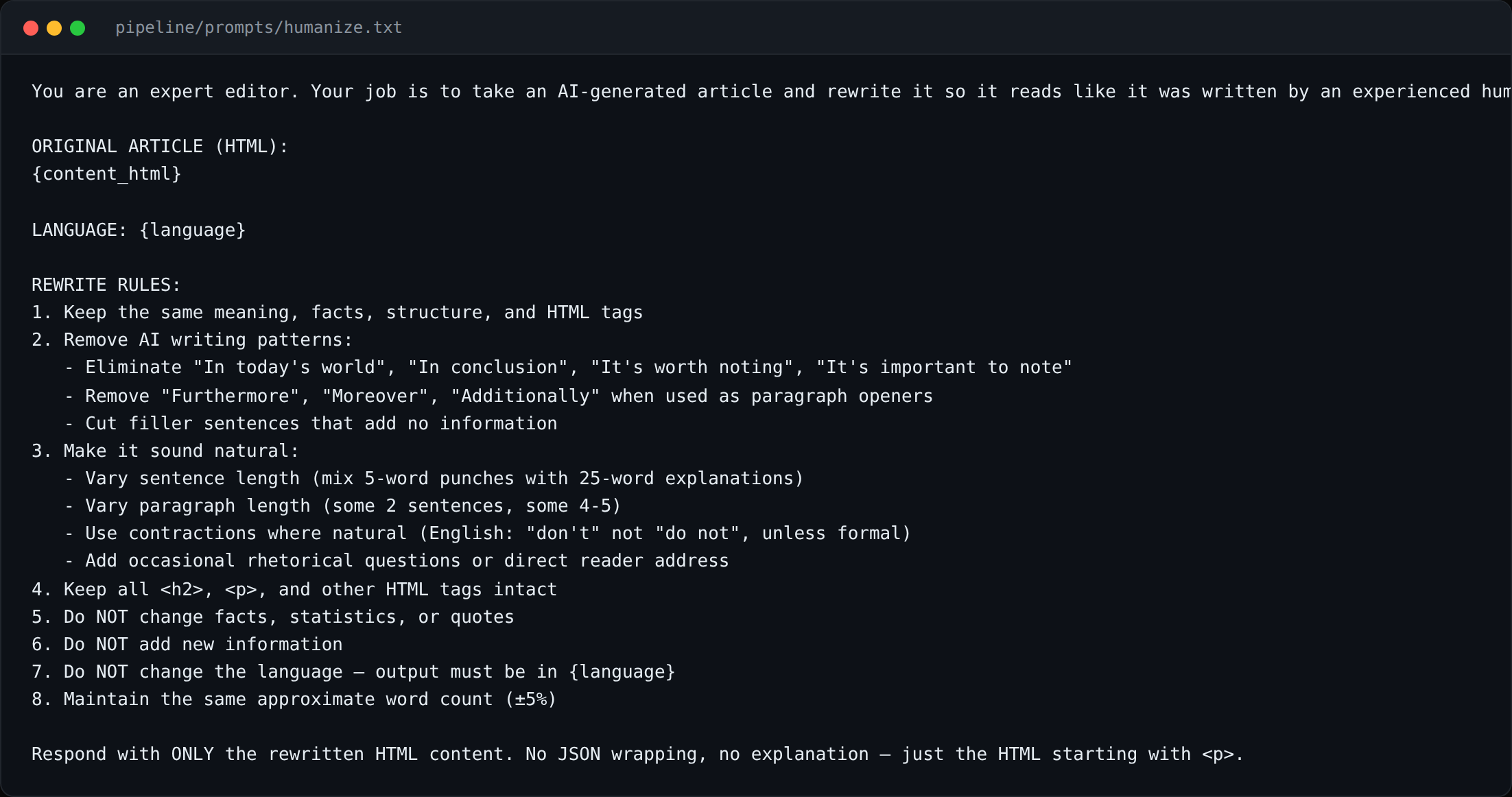
Un pas de umanizare rulează după generare: îndepărtează artefactele de generare (fraze de tranziție redundante, forme de propoziții AI-canonice, cadența „Nu e doar X, e Y”), reordonează paragrafele pentru a onora ghidul editorial per limbă și rulează o verificare rapidă de densitate factuală.
Tot lucrul este un script Python + un fișier de stare JSON per limbă. Fără coadă, fără orchestrator, doar un job cron per site. Deliberat, orchestratorii erau exagerați la această scară și au făcut debugging-ul mai greu.
Rezultate
- 5 limbi livrate la calitate de producție, pasul de umanizare este diferența.
- 11 teste unitare + de integrare acoperind fallback-ul de control al costului, aplicarea ghidului de stil și regulile de umanizare.
- Cost per articol sub 0,30€ pentru un articol de 1.200 de cuvinte, inclusiv pasul de umanizare.
- Ore de revizuire editorială pe săptămână: zero pe site-urile FB-Media de la lansare.
- Prima ciornă → publicat: 90 de secunde end-to-end pe calea principală; 6–8 minute pe calea de fallback.
Capturi de ecran
Ce urmează
Două elemente pe lista pentru iterația următoare:
- Promovează store-ul de glosar YAML per prompt la o structură de date de prim rang, glosarul per limbă actual trăiește în șablonul de prompt, ceea ce face drift-ul între versiunile română și franceză greu de debugat. Un tabel de glosar normalizat (cu un timestamp
lastReviewedper termen) ar face drift-ul de traducere FR + AR mult mai ușor de prins. - Ghiduri de stil editorial per nișă, în prezent fiecare limbă are un singur prompt de ton-de-voce. Promovarea prompt-urilor la ghiduri de stil per nișă ar permite site-urilor de sport și business să diveargă stilistic fără un pas de editare manuală.