Contexte
La plupart des pipelines de contenu multilingue produisent un texte qui se lit comme traduit. On peut repérer les coutures, calques, mismatches de registre, idiomes qui survivent quand ils ne devraient pas, particularités de markup qui trahissent la langue source. Polyglot Content a été construit pour livrer du copy qui se lit comme s’il avait été écrit par un local depuis le début.
Il a commencé sa vie comme backend de génération d’articles pour les sites d’éditeur roumain FB-Media. Une fois la passe d’humanisation en place, le mouvement évident était de généraliser : même moteur, cinq langues, guides éditoriaux par langue.
Brief
- 5 langues de lancement : anglais, roumain, français, arabe, allemand.
- Style éditorial par langue, la voix d’actualités en registre formel roumain diffère de la voix de magazine français, qui diffère de l’arabe MSA.
- Chaîne de fallback : modèle rapide et bon marché pour la première ébauche, modèle lent et cher pour la passe d’humanisation.
- SEO par locale, hreflang, canonical, soumission search-console, sitemap conscient de la locale.
- Cible de build : 1 000 à 1 200 mots par article dans n’importe quelle langue, en tenant la voix sur la longueur.
- Inférence local-first quand possible, Ollama sur un GPU de station comme fallback contrôlé en coût.
Architecture
Stratégie de modèle à deux niveaux :
- Primaire : Claude Sonnet (via le proxy Claude Code CLI qui enveloppe l’abonnement, donc le coût par article est fonctionnellement nul).
- Fallback : qwen3:14b sur Ollama, tournant sur un RTX 4070 Ti Super de station.
Quand le proxy expire (rare) ou retourne une réponse malformée (encore plus rare), la pipeline bascule sur le modèle local sans intervention de l’opérateur. Les deux produisent dans la fourchette 1 000–1 200 mots ; Claude est plus précis sur le registre, qwen est un brin plus verbeux.
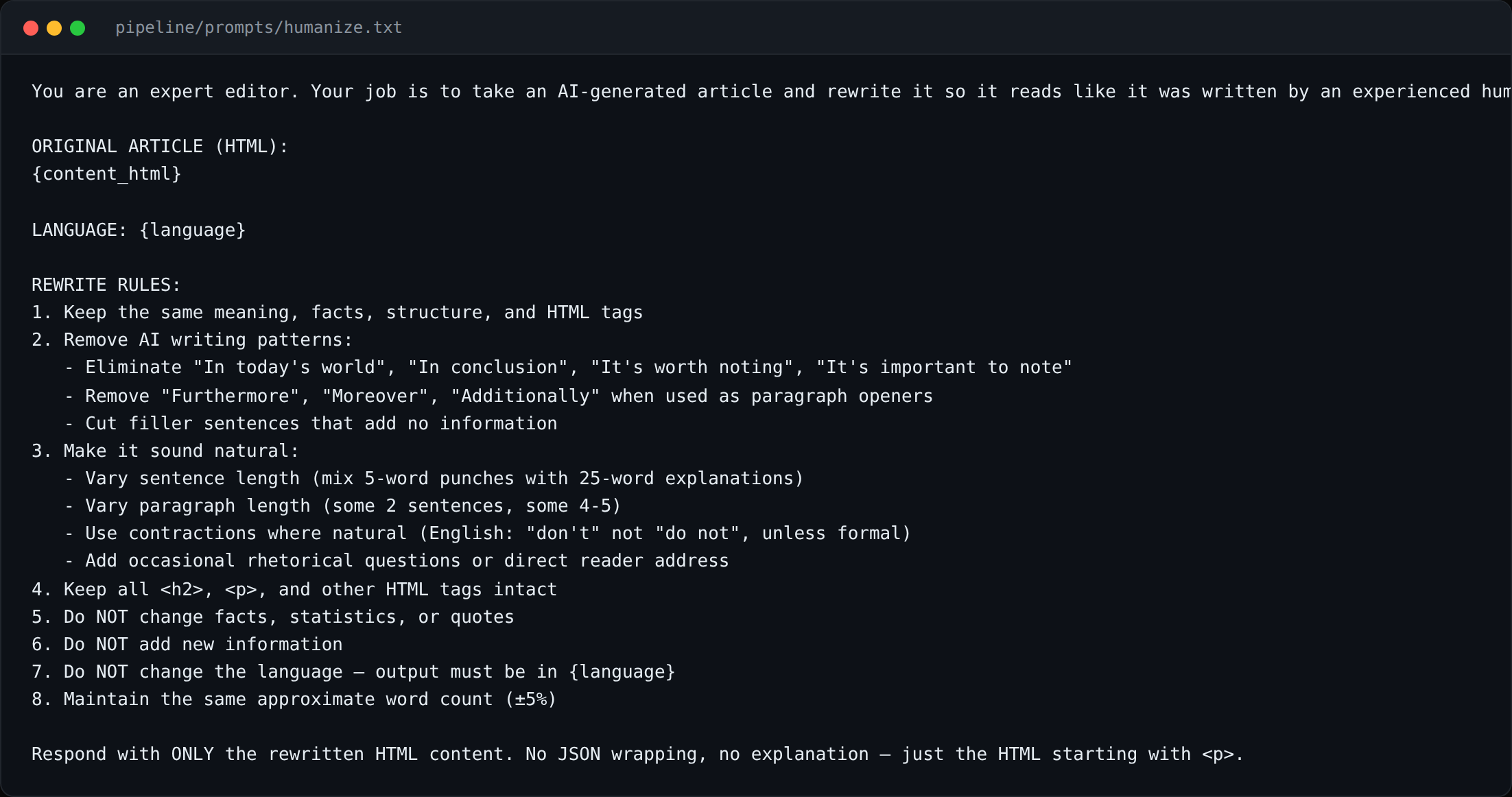
Une passe d’humanisation tourne après la génération : elle retire les artefacts de génération (phrases de transition redondantes, formes de phrases AI-canoniques, la cadence « Ce n’est pas juste X, c’est Y »), réordonne les paragraphes pour honorer le guide éditorial par langue, et fait une vérification rapide de densité factuelle.
Le tout est un script Python + un fichier d’état JSON par langue. Pas de file, pas d’orchestrateur, juste un job cron par site. Délibéré, les orchestrateurs étaient surdimensionnés à cette échelle et ont rendu le débogage plus difficile.
Résultats
- 5 langues livrées en qualité production, la passe d’humanisation est la différence.
- 11 tests unitaires + d’intégration couvrant le fallback de contrôle du coût, l’application du guide de style, et les règles d’humanisation.
- Coût par article sous 0,30 € pour un article de 1 200 mots, passe d’humanisation incluse.
- Heures de revue éditoriale par semaine : zéro sur les sites FB-Media depuis le lancement.
- Première ébauche → publié : 90 secondes end-to-end sur le chemin primaire ; 6–8 minutes sur le chemin de fallback.
Captures
La suite
Deux éléments sur la liste de la prochaine itération :
- Promouvoir le store de glossaire YAML par prompt vers une structure de données de premier rang, le glossaire par langue actuel vit dans le template de prompt, ce qui rend le drift entre les versions roumaine et française difficile à débugger. Une table de glossaire normalisée (avec un timestamp
lastReviewedpar terme) rendrait le drift de traduction FR + AR beaucoup plus facile à attraper. - Guides de style éditorial par niche, actuellement chaque langue a un seul prompt de tone-of-voice. Promouvoir les prompts à des guides de style par niche permettrait aux sites sport et business de diverger stylistiquement sans une passe d’édition manuelle.